

[1][2][3][4][5][6][7][8][9][10][11][12][13][14][15]
距离上一篇打造音乐创作AI(一)已经过去一年多了, 一直忙于工作和家庭,音乐算法研究进展甚微。 最近看到了NotaGen[15:1]的发表,堪称符号算法作曲领域的里程碑式工作。 不得不承认,自己还在半山腰磨蹭,别人已经把旗子插上山顶了。 索性第二篇就介绍一下NotaGen,自己这边的思路以后再整理吧。
这篇由中央音乐学院与多所大学联合团队发表的工作,无论从算法路线和数据来源都做得非常完备。 不仅发表了论文,也开放了源代码和Demo。 当然最宝贵的数据集并没有放出(可能是考虑版权问题)。
除了官方Demo,这里给出一些我自己使用NotaGen生成的键盘作品(曲谱图片可点开大图):





















依据paper和源代码这些可观察到的内容,以下从三个要点来简要介绍一下NotaGen的工作。
Interleaved ABC Notation
音乐作为一种时序模态,自回归模型始终是生成的首选方法。 这种方法的本质是训练一个“文字接龙”式的语言模型,只需构造一种语言来描述目标模态(术语称为tokenize), 剩下的工作就可以交给transformer[1:1]等主干模型完成。 如今,甚至连图像生成也逐渐向自回归模型靠拢,不过也有反其道而行之的尝试,用扩散模型来处理自然语言。
与音频生成任务不同,符号音乐生成的主要难度不在算法层面,而是数据表示和高质量的数据来源。
常见的五线谱数字化语言有MusicXML、MEI、ABC Notation、Lilypond、Humdrum这么几种。 其中,MusicXML和MEI基于XML,文本冗余度较高。ABC Notation和Lilypond是专用语言, Lilypond的语法类似于Latex,灵活性较高,描述能力强但表达方式多变,不利于模型学习。 笔者在上一篇中介绍了自己基于Lilypond发明的变种语言Paraff,此处不再赘述。 剩下的ABC Notation和Humdrum两种语言都有人用来做符号音乐算法的数据表示。 Humdrum更像是一种表格,而不太像一种语言,个人不太喜欢。
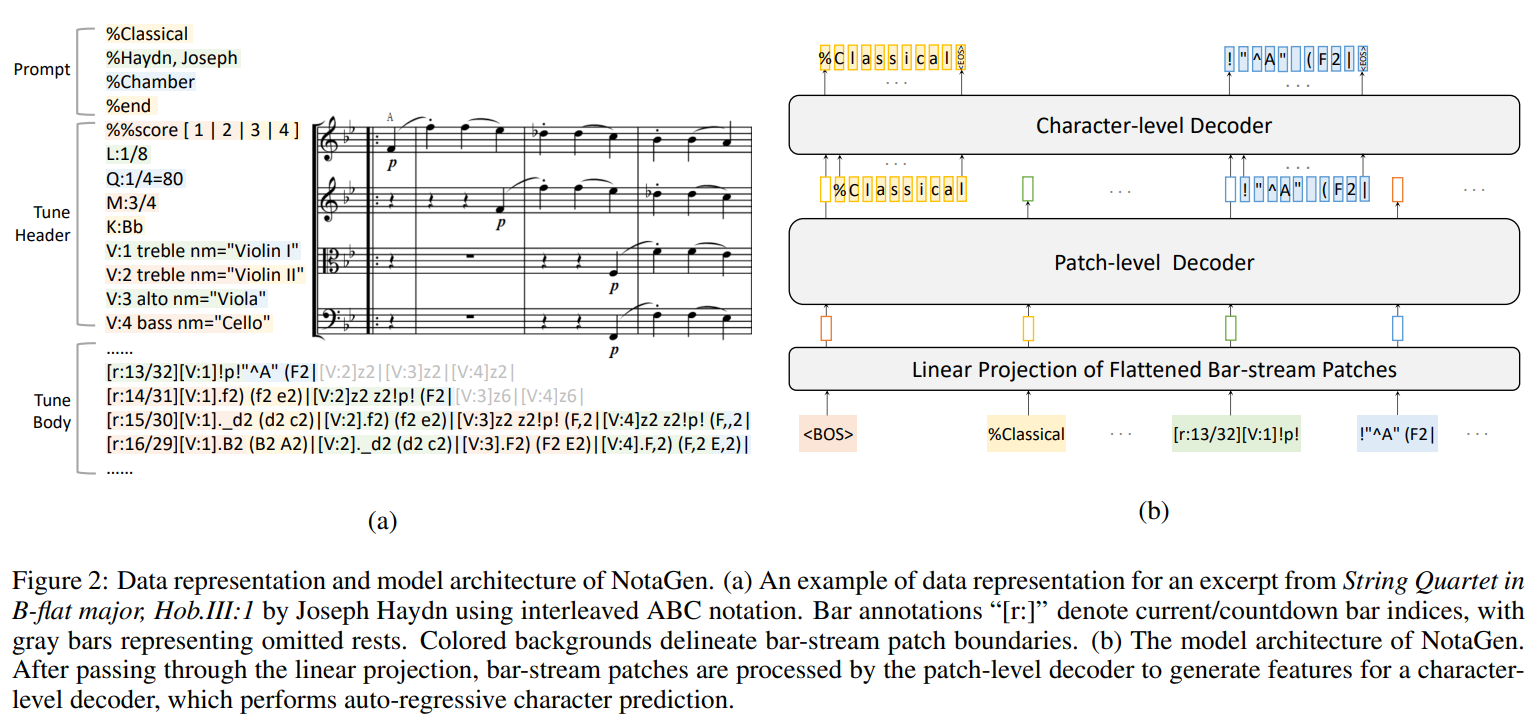
NotaGen使用的是ABC Notation的一种变种——Interleaved ABC Notation。 Interleaved ABC Notation可能最早由MuPT[11:1]的作者提出, 也可能是CLaMP 2[12:1]的作者WU独立设计的。毕竟思路很简单,即将曲谱从part-wise表示转换为time-wise表示。 笔者的Paraff也遵循同样的设计。 见下图:
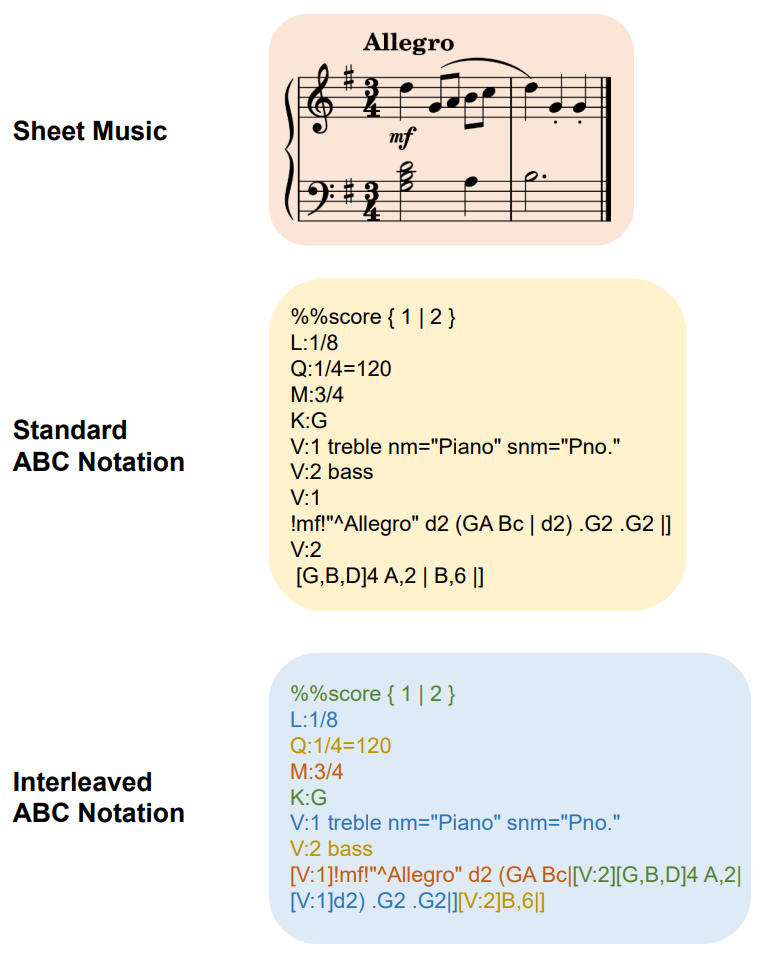
Figure 6 from CLaMP 2 图中以Chopin Op.9 No.2 前两小节为例
原始的ABC Notation是part-wise,或称voice-wise,从头到尾描述完一个声部再写下一个声部。
而Interleaved ABC Notation是time-wise,完整描述一个小节的所有声部后再写下一个小节。
笔者之前没有采用ABC Notation的原因是,其自带的曲谱渲染器太过于简陋。 而笔者的主要工作领域之一是OMR,需要高质量的曲谱图像数据。从生成数据的角度看,Lilypond显著优于ABC Notation。 不过,NotaGen和CLaMP团队解决了ABC Notation到MusicXML的转换问题,并使用MuseScore作为曲谱渲染器及多种媒体格式的转换工具。 这使得ABC Notation成为一个不错的选择,但对于复杂曲谱(如复调键盘作品),ABC Notation的表达能力仍有待观察。
MuseScore是商业级曲谱软件中唯一开源的,类似的方案还有Verovio。 不过,当MuseScore开源时,笔者已经开发了自己的Lotus项目。 一旦转型需要进行大量额外的前端工作,因此没有深入使用。
2 Levels Decoder
使用ABC Notation来做符号音乐生成,可能最早的是MuPT[11:2]。 查看其论文,除了数据表示外,几乎没有太多关于音乐方面的内容,主要探讨的是数据集相关的Scaling Law。 给我类似印象的还有Music Transformer[2:1],除了实现了MIDI数据的tokenization,其他主要是提出了一种优化transformer二次方复杂度的方法。 不过,NotaGen团队在模型架构方面显然更有追求。 确切地说,是第二作者(或者应该称为同等贡献作者之一)Shangda Wu再次应用了他之前提出的一种两级解码架构。
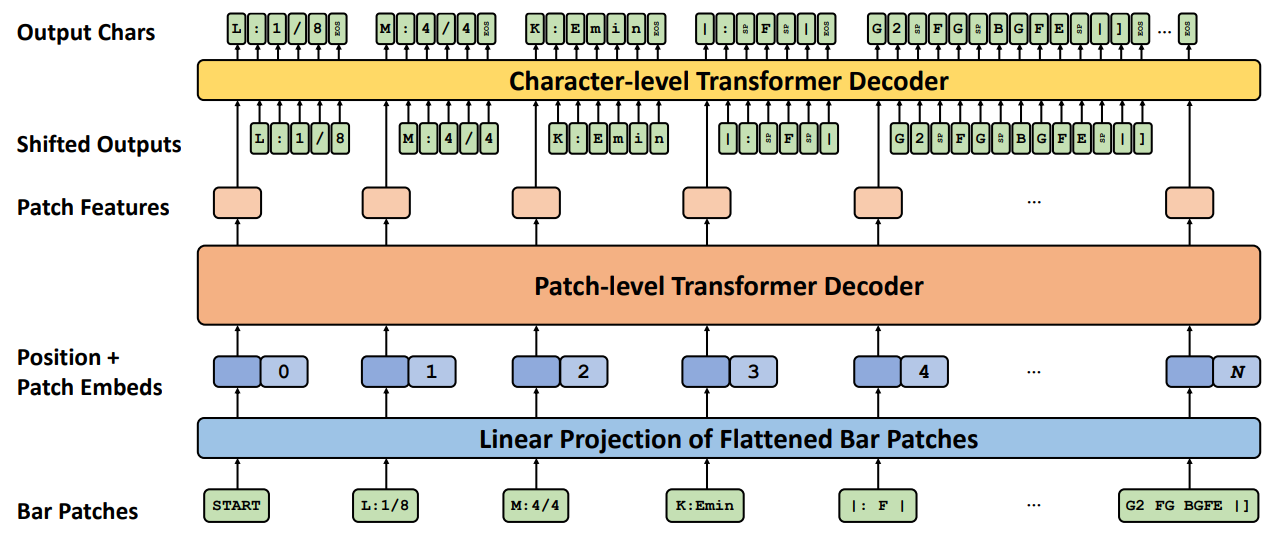
笔者第一次看到这里马上联想到之前的一篇MegaByte[7:1]:
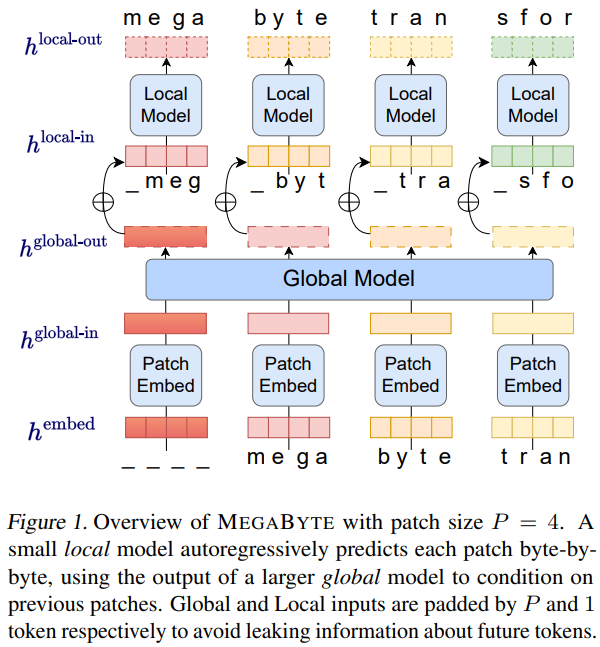
然而查看发表日期,WU的TunesFormer[5:2]还是在MegaByte[7:3]之前。 但是在bGPT[10:1]的论文中,作者又亲自提到是受了MegaByte的启发。 所以究竟是独立提出的想法还是借鉴了更早的工作,笔者还无法下定论。
两级解码器的思路来源是清晰的,其目的是缓解注意力机制中的序列长度问题。 即使按照MuPT[11:3]的路线,有了目前推理加速领域的技术支持(如FlashAttention),一首音乐的长度似乎也不再是问题。 然而在符号音乐领域,有一个天然可以利用的结构——音乐中周期性的强弱节奏构成的小节—— 使得符号音乐在时间轴上天生具有二级结构,不加以利用就显得浪费了。
笔者在前一篇中构造的单小节曲谱编/解码器也是基于类似的思路。 不过这里的区别在于,笔者之前的设计将网络参数的重点放在token这一级(对应NotaGen的byte level), 而bar-level在最终解码时仅作为前情提要式的信息辅助。训练时,bar-level的小节编码器只关注单个小节, 并作为token-level训练的预训练模块加载。 而在NotaGen中,bar-level解码器才是作曲的主角,它把整个小节当成一个“token”来处理。 这里打引号的token其实是潜在空间中的一个向量,一小节内容岂是一个词能概括的。 不过前一篇中笔者的工作也证明了,一小节音乐内容的确能够压缩到一个几百维的向量中。 然后byte-level解码器仅关注单个小节信息,完全不看上下文。 缩小关注范围带来的另一个好处是,连BPE tokenizer也省去了。
这里的关键在于,虽然两级联合训练的思路并不难想到,但这样做其实是有代价的。 在权衡各种解法利弊时,这种方法会被过早淘汰出关注视野。 就像下棋一样,有时最优的一步会出现在看似不可能的地方。 这里的代价是,为了高效地同时训练两级解码器,byte-level的输入数据长度需要强制对齐, 这会牺牲一部分很长的小节(例如一长串快速短音符或连续多组复杂和弦)。 从结果来看,NotaGen的设计很可能是做出了正确的取舍。
顺便一提,这个两级解码器结构在WU的工作中更多用于音乐信息检索(MIR)领域,见于CLaMP 1-3[6:1][12:2][14:1]。 在bGPT[10:2]中,还尝试了使用该架构生成图像、音频以及CPU状态预测。
CLaMP-DPO
在模型训练方面,NotaGen也沿袭了目前LLM主流的pretrain-finetune-RL的路线范式。
从源代码来看,每个阶段都是全量参数的训练,没有使用LoRA等附加参数方法。除了数据集和损失函数的变化,不同阶段仅调整了学习率。
值得说一下的是强化学习阶段,作者复用了自己之前的工作CLaMP 2[12:3]作为评估模型。 CLaMP 2原本用于MIR任务,提取每首曲子的音乐特征。 在这里相当于RLHF中的打分模型,用于比较finetune后模型生成的作品与相同提示下参考作品在语义特征上的相似度。 在生成时,使用的提示是一个三元组:(时代,作曲家,体裁)。 在每一种提示组合下,把所有生成作品按最优相似度排序,其中前10%进入接受集,末尾10%进入拒绝集。 训练时,从接受集和拒绝集中各采样一个样本组成正负样本对$(pw, pl)$,然后计算DPO-Positive[16]损失函数:
$$ \mathcal{L}_{\text{DPOP}}(\pi_\theta; \pi_{\text{ref}}) = -\mathbb{E}_{(p, x_{pw}, x_{pl}) \sim \mathcal{D}} \left[ \log \sigma \left( \underbrace{ \beta \log \frac{\pi_\theta(x_{pw} | p)}{\pi_{\text{ref}}(x_{pw} | p)} - \beta \log \frac{\pi_\theta(x_{pl} | p)}{\pi_{\text{ref}}(x_{pl} | p)} }_{\text{DPO items}} - \underbrace{ \beta \lambda \cdot \max \left( 0, \log \frac{\pi_{\text{ref}}(x_{pw} | p)}{\pi_\theta(x_{pw} | p)} \right) }_{\text{DPOP item}} \right) \right] $$补充说两句,笔者在算法开发中有一种体会,分析模型和生成模型的训练是相辅相成的。 这里的分析模型是指输入数据的熵高于输出数据的模型,生成模型则相反。 分析模型在于排除噪声干扰,识别数据中存在的某种潜在模式,而生成模型则通过混入噪声(或从噪声出发),并引向目标分布内的多样性维度。 笔者最初训练曲谱生成模型是为了作为OMR的数据来源,通过生成符合真实分布的曲谱数据来合成有标注的曲谱图像。 反之,更好地识别曲谱中的各种模式则有利于条件化地控制音乐生成。
其他
除了以上三点,想必还有大量工作隐藏在数据集的制备中,包括清洗、格式转换工具开发等。 尤其是其中数据来源表格中的Internal Sources一项,想必是中央音乐学院得天独厚的资源。 就算你穷尽其他开放来源也才凑齐不到人家三成!
| Data Sources | Amount |
|---|---|
| DCML Corpora | 560 |
| OpenScore String Quartet Corpus | 342 |
| OpenScore Lieder Corpus | 1,334 |
| ATEPP | 55 |
| KernScores | 221 |
| Internal Sources | 6,436 |
| Total | 8,948 |
当然,尽管作为里程碑之作,NotaGen目前仍存在一些不足之处。 一是伴奏声部的编曲整体来看偏于简单,缺乏浪漫主义时期那种复杂多声部的丰富编排。 这一点从听感上可能不太明显,但对于基于五线谱的算法作曲方向来说,清晰的声部逻辑正是该方向追求的特色之一。
另外,NotaGen模型还可以观察到一定程度的过拟合现象。 也就是说,它可能直接记住了训练集中的部分曲谱。 例如以下这两首:
过拟合有时可以被视为一种积极的信号,意味着通过继续扩大数据集可以获得更多收益。 目前,一个潜在的曲谱数据来源是国际音乐库IMSLP。 有朝一日能够将IMSLP上近7万部名家名作的PDF曲谱数字化,可用的数据量至少还能增加一到两个数量级。
References:
Transformer: arxiv1706.03762 ↩︎ ↩︎
Music Transformer: arxiv1809.04281 ↩︎ ↩︎
MusicBERT: arxiv2106.05630 ↩︎
Deep Choir: arxiv2202.08423 ↩︎
TunesFormer: arxiv2301.02884 ↩︎ ↩︎ ↩︎
CLaMP: arxiv2304.11029 ↩︎ ↩︎
MegaByte: arxiv2305.07185 ↩︎ ↩︎ ↩︎ ↩︎
Mamba: arxiv2312.00752 ↩︎
MambaByte: arxiv2401.13660 ↩︎
bGPT: arxiv2402.19155 ↩︎ ↩︎ ↩︎
MuPT: arxiv2404.06393 ↩︎ ↩︎ ↩︎ ↩︎
CLaMP 2: arxiv2410.13267 ↩︎ ↩︎ ↩︎ ↩︎
Music Event Transformer (MET): https://github.com/SkyTNT/midi-model ↩︎
CLaMP 3: arxiv2502.10362 ↩︎ ↩︎
NotaGen: arxiv2502.18008 ↩︎ ↩︎ ↩︎ ↩︎
DPO-Positive: arxiv2402.13228 ↩︎ ↩︎
DPO: arxiv2305.18290 ↩︎