
以本篇作为起始,计划写一个算法作曲相关的系列,记录一些音乐算法研发中的想法。
起源
2018年Google发布的Music Transformer是算法作曲中具有里程碑意义的工作。 它证明了自回归模型在音乐领域中的巨大潜力。 其中一个值得重视的基础性工作在其paper附录中,关于如何把MIDI格式编码成易于自回归模型训练的token序列。
后来在笔者的OMR项目上线完成后(OMR项目的心得笔者将另开系列分享), 笔者发现借助OMR技术的能力,完全可以另辟蹊径,尝试开发一套基于五线谱的音乐生成模型。 相对MIDI来说,由于直接来自于作曲家,五线谱的符号系统更接近自然语言。 从信息科学角度来说,其编码形式的信息熵密度更大,这是有利于机器学习的。 当然缺点也很明显,作为音乐格式,五线谱不像MIDI可以直接播放成声音,阅读门槛较高。 不过这个可以靠开发曲谱演奏模型来弥补。 而反过来,由于五线谱易于表达音乐构思和指导演奏,把音频和MIDI转成曲谱(即扒谱)也是一个很有价值的方向。 无论如何,开发一个可以写作曲谱的AI agent的想法总是很诱人的。
设计一门语言
开发一个曲谱的生成模型,首选要解决的是选定一种用来表达曲谱的语言。 就像Music Transformer做的一样,要使用自回归模型生成一种数据格式,就要先处理这种格式的tokenization。 而可用的token方案需要满足两个条件:
- token上有明确定义的序,即各token的先后顺序的规则是明确可学习的。
- 语法上是鲁棒的。
对于自然语言和MIDI来说第一条都是天然满足的,但对五线谱来说则是个问题。 五线谱中每个音乐事件同时存在(时间,声部,音高)三个坐标维度。 并且由于存在空间拥挤性,时间上同时发生的多个事件在图像中也没有跟x轴简单对应起来,例如下图:

顺理成章地,我们会想到五线谱的标准数字格式语言是一个选择。 首先要排除掉Music XML和MEI这类基于XML的格式,太过繁复,破坏了信息熵原则。 诸如Lilypond和ABC Notation这样的音乐DSL则可以在考虑之列。 但这时我们就碰到了第二个问题,DSL通常很复杂,语法是不鲁棒的。 自回归采样的概率性质不可避免会引入语法错误。 由于MIDI格式足够简单,对应的token方案可以通过简单规则忽略掉异常token,而曲谱DSL则做不到 (MIDI的tokenization方案可以采用累加性时间token,而五线谱的时间表达以节拍为基准,是一套复杂的分数系统)。 这就要求我们重新设计一种便利语言生成模型训练的新曲谱语言。 它应具有简单的上下文无关文法,这样的自回归生成采样时就可以采用简单的技术手段来规避语法错误。
这门新的语言笔者将之命名为“Paraff”,其名字来源于Lilypond中的parallel记法。 下面是Paraff的“Hello World”:

对比MusicXML的这个例子,你会发现Paraff有多么简洁
Paraff的相关文档,包括词汇表、语法解释器和格式转换工具等,之后整理好笔者会发布在Github上。
自动编码器
Music Transformer作者的一个重要贡献是优化了Transformer二次方复杂度的问题,从而提升了模型处理的序列长度,使得生成的音乐具有超过1分钟的长时间结构。 而基于五线谱的生成模型则适于从另一个思路来处理序列长度问题。 与MIDI不同的是,曲谱天然具有良好的单元结构,即小节(measure)。 因此音乐生成可以自然地建模为两级结构: 第一级以Paraff的单词作为token,一小节曲谱为一句子,处理短期注意力; 第二级以小节的embedding为序列元素,一首乐曲为一句子,处理长期注意力。 (当然在第二级,embedding不是token,并不能单独用于自回归,所以两级是结合在一起训练的。)
下文重点讨论五线谱中一个小节的embedding如何获取,其他问题留待续篇。
设想现在我们已经有了大量由Paraff语言表达的单小节曲谱样本, 我们目标是把每个样本含有的信息抽象成一个d维(譬如d=256)向量, 最自然想到的当然是VAE。 本文不详述VAE(变分自动编码器)的基本原理(推荐去读科学空间博主的相关系列), 笔者假定读者已了解相关背景知识,这里仅以下图回顾经典VAE的结构:
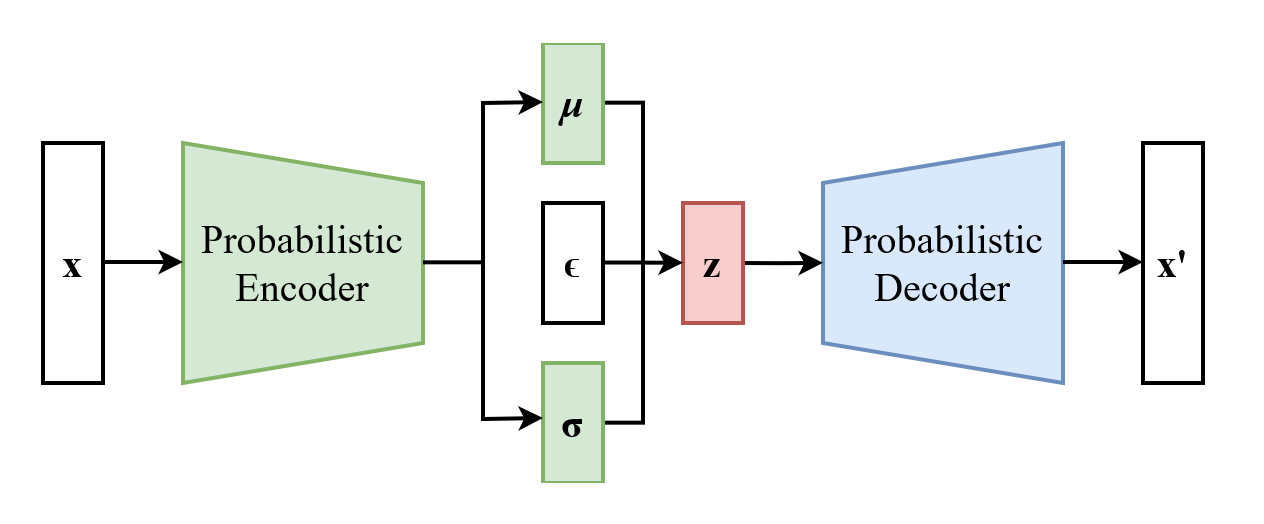
如果以自回归模型作为VAE的decoder,则decoder在推断阶段是多步运行的, 并且decoder的输入并不只是z,还伴随一个x’的"半成品"。 我们观察到无论encoder还是decoder,其主要任务都是分析理解一个序列, 区别只在于encoder目标为压缩信息,而decoder目标则是预测下一个词的概率分布。
基于此,笔者提出一种 encoder和decoder共享大部分权重的新网络结构,即shared VAE。 其中encoder和decoder共享一个transformer的主干网络。如下图:

Encoder的输出经过reparameter之后,附加到一个特殊token MSUM (意为Measure Summary)的embedding之上,
decoder可据此来还原完整的句子。
从被训练的主干transformer视角来看,它的任务是,如果看到一个中间词(含BOM)则预测下一个词,
如果看到结束符EOM(end of measure)则给出全句概括。
也就是一人可以身兼encoder, decoder两份工作。
最后为了验证这样训练出来的编码器是否能够精确反映原始样本的信息,笔者做了一个试验, 将reparameter中的σ数值手工设为常量,观察重构样本的变化,结果如下:
x| |
| |
| |
| :-- | :-- | :-- | :-- | :-- | :–
x’σ=0|
:-- | :-- | :-- | :-- | :-- | :–
x’σ=0| |
| |
| |
| x’σ=4|
x’σ=4| |
| |
| |
| x’σ=8|
x’σ=8| |
| |
| |
| x’σ=16|
x’σ=16| |
| |
| |
| x’σ=32|
x’σ=32| |
| |
| |
| x’σ=100|
x’σ=100| |
| |
| |
|
试验中选取的原始样本x全部来自无条件随机生成,不包含于shared VAE训练集。
分析之前先回顾一下reparameterization公式: $$ z=\mu + \sigma \epsilon $$ 其中z, μ, ε都是d维向量,$\epsilon \sim {\mathcal {N}}(0,1)$。
从试验结果可见,当σ<8时,重构样本与原始样本几乎没有可观察的差异。 这表明通过encoder获得的编码不仅精确反映了原始样本的信息,并且对噪声干扰还有很强的鲁棒性。
这里还有一个问题值得讨论一下。 试验观察到encoder输出的μ向量模长在1附近(VAE先验loss的要求μ尽量小), 那么一个特征向量是如何对抗标准差8倍于自身模长的高斯噪声的污染,还能顺利给decoder传达信息呢? 笔者认为唯一的可能性在于,向量维数d=256的选择带有很大的冗余(当然前提是主干网络得到了充分训练), decoder得以能够从少数污染较轻的向量分量中还原出原始的μ值。 这类似于QRCode的容错原理——部分遮挡的二维码仍能被识别出来,道理相同。
换个角度,从几何直观来讲,假如绝大多数曲谱对应的μ分布在d维空间中一个低于d维的超平面M上, 高维空间中随机选取的噪声向量ε大概率与超平面M垂直(几乎)。 这样decoder有一个简单策略,把z投影到M上就得到了μ的近似。 当然实际上μ的分布很可能是个形状复杂的流形,但原理上大致类似。
至此,我们实现了单个小节五线谱的编码器。其应用于音乐生成的具体细节留待后续文章。